
5年前にアカウントだけ作ったきりだったkaggle。
「いつかやろう」と思いながら、本を買っては積読になっていた・・・。
というのも、チュートリアル的な「Titanic」をやった後に何をすればよいのかが分からない。やたら難しいコードコンペやら、画像解析やらが多くて、チュートリアルからのギャップが大きすぎる。
そんな中で、先日たまたま「初心者はPlayground Seriesから入るのが良い」的なブログを見た。
どうやらPlaygroundSeriesは初心者向けでkaggleが開催しているテーブルデータのコンペのよう。毎月実施しているみたい。ただ、メダルや賞金はなし。上位3人はkaggleグッズがもらえるらしい。
なるほど!と思い、早速参加してみた。
「Backpack Prediction Challenge」
簡単に言うと、「バックの価格を予想して、予測精度を競おう!」というもの。
結果からお示しすると、3393チーム参加のうちの392位でした。
上位者のコードも公開されている中で順位はあまり重要ではないけど、初心者なりにkaggleの進め方等経験できたのは良かった!Playground Seriesはおすすめ!
以下、ほぼ備忘録です。せっかくの初コンペ、なるべく文字化しておきたい。
目次
分析してみた
教科書的ですが、分析の大きな流れは下記(たぶん)。
1.ライブラリ・データ読み込み
これは定型的な作業です。ライブラリインポートして、データを読込む。
最初にすべてのライブラリをインポートしておくべきですが、途中で抜け漏れに気づいて追加インポートしてたりするのはご愛敬。
#ライブラリのインポート
import numpy as np
import pandas as pd
from pandas import DataFrame, Series
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
#データの読み込み
df = pd.read_csv('../input/playground-series-s5e2/train.csv')
df_test = pd.read_csv('../input/playground-series-s5e2/test.csv')
submission = pd.read_csv('../input/playground-series-s5e2/sample_submission.csv')
#追加データ
train_extra = pd.read_csv("../input/playground-series-s5e2/training_extra.csv")
df = pd.concat([df,train_extra],axis=0,ignore_index=True)
2.データの概観確認・EDA(探索的データ分析)
下記のような感じで、データを確認していきました。
ydata profiling(旧pandas-profilingは非常に便利。データの各統計量をまとめてレポート出力してくれる。
このデータの特徴は、各変数間の相関が殆ど0に近しく、ノイズが非常に多いということでした。
通常なら、革製品の方が高価だったり、ブランドによる価格差が出たりしますが、特段そのような傾向は見られない。
というのもkaggle運営が恣意的に作成したデータセットのため、ランダムなデータが多数含まれているのが理由みたいです。
print('訓練データのデータ数は{}、変数は{}種類です。'.format(df.shape[0], df.shape[1]))
print('テストデータのデータ数は{}、変数は{}種類です'.format(df_test.shape[0], df_test.shape[1]))

print(df.head())
print(df.columns)
print(df_test.head())
print(submission.head())

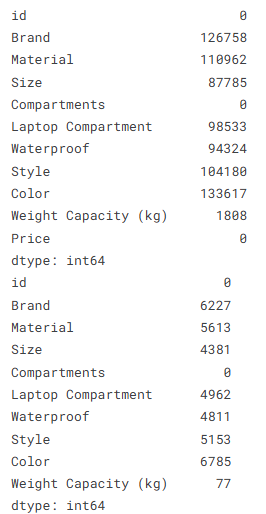
#欠損値確認
print(df.isnull().sum() )
print(df_test.isnull().sum() )
#レポート出力
from ydata_profiling import ProfileReport
profile = ProfileReport(df, title="Profiling Report")
profile.to_notebook_iframe()
profile.to_file("your_report.html")
3.データ前処理・特徴量作成
kaggleのGrandMaster(めっちゃすごい人)が、「ターゲットエンコーディングが良いよ!」とディスカッションで仰っていたので、パクった。(下記)
こんな方法があるのかと感心しました。第一線にいるプロのコーディングや考え方を学べるのは、kaggleのすごいところだなー。
from cuml.preprocessing import TargetEncoder
TE = TargetEncoder(n_folds=25, smooth=20, split_method='random', stat='mean')
df['pred'] = TE.fit_transform(df['Weight Capacity (kg)'],df.Price)
s = np.sqrt(np.mean( (df.Price-df.pred)**2.0 ) )
print(f"Validation RSME using Target Encode Weight Capacity = {s}")
あと、線形回帰用に以下を実行。(これは自分で書いたけど、結局使わなかった笑)
# 欠損値を最頻値で入力
for column in df.columns:
most_frequent_value = df[column].mode()[0]
df[column] = df[column].fillna(most_frequent_value)
for column in df_test.columns:
most_frequent_value = df_test[column].mode()[0]
df_test[column] = df_test[column].fillna(most_frequent_value)
#カテゴリデータのOne-Hot-encoding
df = pd.get_dummies(df, columns=['Brand'], dtype=int)
df = pd.get_dummies(df, columns=['Material'], dtype=int)
df = pd.get_dummies(df, columns=['Size'], dtype=int)
df = pd.get_dummies(df, columns=['Style'], dtype=int)
df = pd.get_dummies(df, columns=['Color'], dtype=int)
df_test = pd.get_dummies(df_test, columns=['Brand'], dtype=int)
df_test = pd.get_dummies(df_test, columns=['Material'], dtype=int)
df_test = pd.get_dummies(df_test, columns=['Size'], dtype=int)
df_test = pd.get_dummies(df_test, columns=['Style'], dtype=int)
df_test = pd.get_dummies(df_test, columns=['Color'], dtype=int)
df.isnull().sum()
#waterproof, laptopcompartmentを数値化
df['Laptop Compartment'].replace(['Yes', 'No'], [1, 0], inplace=True)
df_test['Laptop Compartment'].replace(['Yes', 'No'], [1, 0], inplace=True)
df['Waterproof'].replace(['Yes', 'No'], [1, 0], inplace=True)
df_test['Waterproof'].replace(['Yes', 'No'], [1, 0], inplace=True)
また、「勾配ブースティングが最強!」という噂を聞いたので、LightGBMを使ってみた。
決定木を使ったモデルみたいで、LightGBMは欠損値処理やカテゴリ変数の数値化も必要なし。
ただ、欠損値が多いIDは信頼性欠けるよね、ということで、下記のように欠損値の数を集計した変数を作ってみた。(ちょっとだけ精度があがった)
df.isnull().sum()
df["missing_count"] = df.isnull().sum(axis=1)
df_test["missing_count"] = df_test.isnull().sum(axis=1)
4.モデルの構築
線形モデルは結局ボツになったので、lightGBMのみ記録しておく。
と言っても、結局教科書にある定型的なコーディングです。
Oputunaでハイパーパラメータの調整もしてみたけど、精度は少し上がった程度。やっぱり肝はデータの前処理・特徴量の作成なのでしょうね~。
#yとxに分ける
y_lgbm = df_lgbm['Price']
X_lgbm = df_lgbm.drop(['Price', 'id','Weight Capacity (kg)'], axis=1)
X_lgbm_test = df_lgbm_test.drop(['id','Weight Capacity (kg)'], axis=1)
#学習データ検証データに割振り
from sklearn.model_selection import train_test_split
X_lgbm_train, X_lgbm_valid, y_lgbm_train, y_lgbm_valid = train_test_split(X_lgbm, y_lgbm, test_size=0.2, random_state=42)
import numpy as np
import lightgbm as lgb
# カテゴリ変数のリスト
categorical_features = ['Brand', 'Material', 'Size', 'Style', 'Color', 'Waterproof','Laptop Compartment']
# Pandas でカテゴリ型に変換
for col in categorical_features:
X_lgbm_train[col] = X_lgbm_train[col].astype("category")
X_lgbm_valid[col] = X_lgbm_valid[col].astype("category")
X_lgbm_test[col] = X_lgbm_test[col].astype("category")
# LightGBMのデータセット作成
lgb_train = lgb.Dataset(X_lgbm_train, label=y_lgbm_train, categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_lgbm_valid, label=y_lgbm_valid, reference=lgb_train, categorical_feature=categorical_features)
# ハイパーパラメータ設定
params = {
'objective': 'regression',
'metric': 'rmse', # LightGBM の標準メトリックを使用
'boosting_type': 'gbdt',
'learning_rate': 0.1,
'num_leaves': 31,
'random_state': 42
}
# モデルの学習
model = lgb.train(params, lgb_train,
valid_sets=[lgb_train, lgb_eval],
num_boost_round=1000,
callbacks=[
lgb.log_evaluation(period=100), # 100回ごとにログを表示
lgb.early_stopping(100) # 100回連続で改善しなければ早期終了
])
5.予測の出力・提出
これも定型文。アンサンブルやらやってみたけど、一向にスコアはあがらず。
「Trust CV」という言葉も見たけど、初心者からするとLBのスコアを信じる他ない。
#予測出力
lgb_pred = model.predict(X_lgbm_test, num_iteration=model.best_iteration)
#提出
y_pred=lgb_pred
submission['Price'] = list(map(float, y_pred))
submission.to_csv('submission.csv', index=False)
まとめ・感想
初めて学ぶことばかりで、なんだかんだで楽しく参加できました。
本読んで学習するよりも、実際にデータ見て分析しながら学ぶことの方が気づきも多い。そういう意味で、初心者に優しいコンペだなと感じました。(途中DiscussionBord見ても意味分からん議論がされていたりもしたけど・・・)
もう少し慣れてきたら、メダルありのコンペも出てみたい。目指せExpert!