
ちょっと前ですが、Kaggleで「March Machine Learning Mania 2025」に参戦してみた。
アメリカの大学バスケの試合予測をしようというコンペ。
結果は約1700人中500番とイマイチでしたが、これはサッカーにも応用できるのではということで、Jリーグの試合予測モデルを作ってみました。
実行環境は、Googlecolaboを使ってみました。
GPU制限等はあるものの、ブラウザ上で手軽にコード実行できるので大変便利です。
Googleドライブをマウントして、ファイル保管も可能。
# Google ドライブをマウント
drive.mount('/content/drive', force_remount=True)
ssl._create_default_https_context = ssl._create_unverified_context
# Googleドライブ内の保存ディレクトリを指定
save_folder = "J_League_Results"
dir = f"/content/drive/MyDrive/{save_folder}"
os.makedirs(dir, exist_ok=True) # フォルダがなければ作成
スクレイピング
試合データはJリーグ公式サイトからスクレイピング取得を検討。
HPの利用規約には明確にスクレイピングに関する記述はありませんでした。
「robots.txt」で記述のあったdisallowは下記のフォルダなので、これらは避けましょう。
また、記載はなくとも、コード内には待機時間を確保する等、下記記述を入れてサーバー負荷がかかるようなアクセスはしないよう留意します。
time.sleep(5)
下記コードで過去の試合データをスクレイピング取得します。
1994年から2025年までのデータを年ごとに取得して、統合。
##公式サイトからスクレイピング
# 2025年から1994年までのリストを作成
year_list = [str(y) for y in range(2025, 1993, -1)]
# URLの指定
for year in year_list:
try:
url = f"https://data.j-league.or.jp/SFMS01/search?competition_years={year}&tv_relay_station_name="
html = urlopen(url)
bsObj = BeautifulSoup(html, "html.parser")
# テーブルの取得
table = bsObj.find("table", {"class": "table-base00 search-table"})
if table is None:
print(f"{year} のデータが見つかりませんでした。")
continue
rows = table.findAll("tr")
# CSVファイルに書き込み
csv_file_path = f"{dir}/{year}_results.csv"
with open(csv_file_path, "w", encoding="utf-8", newline="") as file:
writer = csv.writer(file)
for row in rows:
csvRow = [cell.get_text(strip=True) for cell in row.findAll(['td', 'th'])]
writer.writerow(csvRow)
print(f"{year} のデータを保存しました。")
time.sleep(5) # サーバーに負担をかけないために待機
except Exception as e:
print(f"{year} のデータ取得中にエラーが発生しました: {e}")
##スクレイピングデータを統合して、ファイル保存
#フォルダ内のすべての CSV ファイルを取得
csv_files = sorted(glob.glob(os.path.join(dir, "*.csv"))) # ファイル名順にソート
# 最初のCSVを基準にヘッダーを取得
df_base = pd.read_csv(csv_files[0]) # 最初のCSVをヘッダーありで読み込む
header_columns = df_base.columns # ヘッダーのカラム名を取得
df_list = [df_base] # 最初のデータフレームをリストに追加
# 2つ目以降のCSVを読み込む
for file in csv_files[1:]:
df = pd.read_csv(file, header=None, skiprows=1) # 2つ目以降はヘッダーなし
df.columns = header_columns[:len(df.columns)] # 列数に合わせてヘッダーを設定
df_list.append(df)
# すべてのデータを1つのDataFrameに統合
merged_df = pd.concat(df_list, ignore_index=True)
# 統合データを保存
merged_csv_path = os.path.join(dir, "all_results.csv")
merged_df.to_csv(merged_csv_path, index=False, encoding="utf-8")
print(f"統合完了: {merged_csv_path}")
データ加工・特徴量作成
列名の変更や、スコアの抽出等、データの加工をしていきます。
特徴量としては、年・チームごとのスコアの平均値等追加。また、年ごとのチームの強さをロジスティック回帰を使って特徴量にします。
season_statistics_Home = df.groupby(["year", 'HomeTeam'])['HomeScore'].agg(funcs).reset_index()
season_statistics_Away = df.groupby(["year", 'AwayTeam'])['AwayScore'].agg(funcs).reset_index()
#各変数・meanで出力されるので変数名統合する
season_statistics_Home.columns = [''.join(col).strip() for col in season_statistics_Home.columns.values]
season_statistics_Away.columns = [''.join(col).strip() for col in season_statistics_Away.columns.values]
season_statistics_Home.columns.values[2] = "HomeScore_mean"
season_statistics_Away.columns.values[2] = "AwayScore_mean"
# シーズンごとに、ロジスティック回帰でチームのwinを説明する
def team_quality(year):
formula = 'win~-1+HomeTeam+AwayTeam'
glm = sm.GLM.from_formula(formula=formula,
data=Year_effects.loc[Year_effects.year==year,:],
family=sm.families.Binomial()).fit()
quality = pd.DataFrame(glm.params).reset_index()
quality.columns = ['Team','quality']
quality['Year'] = year
return quality
また、kaggleで学んだ方法ですが、データを丸々スワップして元データに追加します。単純にデータ量が2倍になります。
def prepare_data(df):
# 勝者と敗者をスワップしたものを用意
# 内容は同じでもデータ量は2倍に
dfswap = df[['year', 'league', 'AwayTeam','HomeTeam', 'Stadium', 'AwayTeamID','HomeTeamID',
'date', 'dow', 'section', 'day', 'AwayScore', 'HomeScore','PointDiff','home',
'AwayScore_mean','HomeScore_mean', 'Awayquality','Homequality','win' ]]
dfswap['home'] ="Away"
df.columns = [x.replace('Home','T1_').replace('Away','T2_') for x in list(df.columns)]
dfswap.columns = [x.replace('Away','T1_').replace('Home','T2_') for x in list(dfswap.columns)]
# 元データとスワップしたものを結合
output = pd.concat([df, dfswap]).reset_index(drop=True)
# dateの昇順でソート
output = output.sort_values(by=['date']).reset_index(drop=True)
# 累積勝利数を計算
output["T1_win_num"] = output.groupby(["year", "T1_TeamID"])["win"].cumsum()
output = output.drop(['T2_Score', 'PointDiff','win'], axis=1)
return output
df = prepare_data(df)
予測モデル
被説明変数には、スコアを。説明変数にはそれ以外とします。
LightGBMで予測します。
#y,xに分解
y = df['T1_Score']
X = df.drop(['T1_Score'], axis=1)
X_test=pred_df.copy()
from sklearn.model_selection import train_test_split
#データ割り振り
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=42)
import numpy as np
import lightgbm as lgb
# カテゴリ変数のリスト
categorical_features = ['league','T1_Team','T2_Team','Stadium','date','dow','home']
# Pandas でカテゴリ型に変換
for col in categorical_features:
X_train[col] = X_train[col].astype("category")
X_valid[col] = X_valid[col].astype("category")
X_test[col] = X_test[col].astype("category")
# LightGBMのデータセット作成
train = lgb.Dataset(X_train, label=y_train, categorical_feature=categorical_features)
eval = lgb.Dataset(X_valid, label=y_valid, reference=train, categorical_feature=categorical_features)
# ハイパーパラメータ設定
params = {
'objective': 'regression',
'metric': 'rmse', # LightGBM の標準メトリックを使用
'boosting_type': 'gbdt',
'learning_rate': 0.1,
'num_leaves': 31,
'random_state': 42
}
# モデルの学習
model = lgb.train(params, train,
valid_sets=[train, eval],
num_boost_round=1000,
callbacks=[
lgb.log_evaluation(period=100), # 100回ごとにログを表示
lgb.early_stopping(100) # 100回連続で改善しなければ早期終了
])
# 予測
pred = model.predict(X_test, num_iteration=model.best_iteration)
y_pred=pred
pred_df['T1_Score'] = list(map(int, y_pred))
pred_df_path = f"/content/drive/MyDrive/J_League_pred/pred_df.csv"
pred=pred_df.copy()
pred=pred[[ 'league','T1_Team','T2_Team','date','T1_Score','home']]
pred.to_csv(pred_df_path, index=False, encoding="utf-8")
pred_df=pred_df[['T1_TeamID','section','T1_Score']]
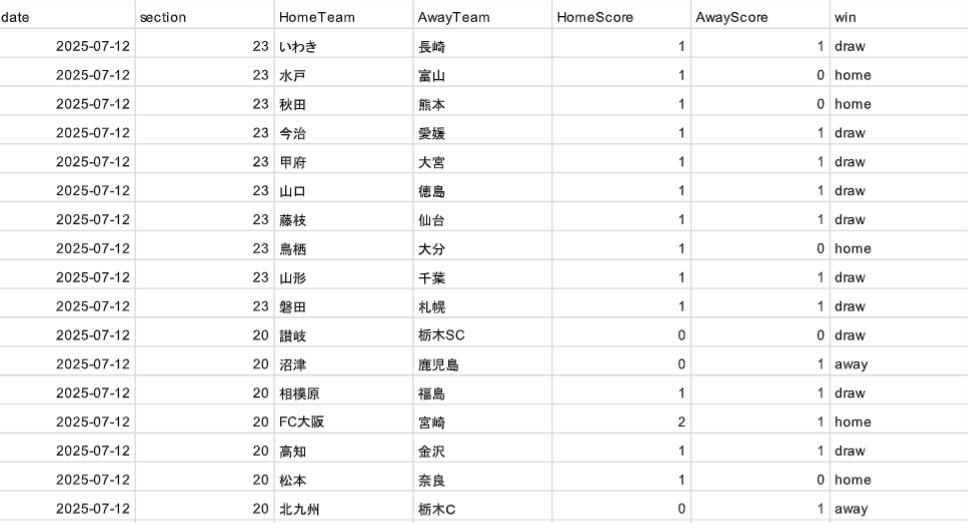
予測結果
各ゲームのスコアを予測することに成功。
今後
アメリカのバスケの予測より、日本のサッカーの予測の方が楽しかったです。
とはいえ、現状はとりあえずモデルは作れたものの、データが貧弱すぎる。
他にも色々データ追加しながら予測精度を上げていきたい!