Python初心者ですが、Webスクレイピングをやってみました。
スクレイピングとは、Webサイト上の文字・画像・URLなどのデータを機械的に収集することです。
以前、「Excelでgoogle一括検索」という記事を書きましたが、こういう単純作業は、できるだけ機械に実行させたいですよね。
今回は、本ブログ記事のタイトルを一括して取得してみました。
環境構築
Pythonのダウンロード
下記URLから、Pythonをダウンロードします。
ライブラリのインストール
ライブラリとは、プログラムの部品をまとめたファイルのことです。
例えば、データの集計をしたい!となったら、NumPy、pandas、Matplotlibなどのライブラリを用いて、計算をしたりします。
また、ライブラリには、Pythonに標準で入っている「標準ライブラリ」と、追加でインストールが必要な「外部ライブラリ」という2種類があります。
Pythonを利用する目的によって、必要なライブラリを使う訳ですね。
スクレイピングの場合は、下記の外部ライブラリが使いやすいようなので、こちらをインストールします。
「requests」:インターネットにアクセス
「Beautiful Soup:HTMLの解析
Windowsの場合は、コマンドプロンプトを起動し、以下のコマンドを打ちます。
pip install requests
pip install beautifulsoup4
“successfully installed”とでたらOKです。
ちなみに、下記コマンドで、インストール済みのライブラリを確認できます。
pip list
エディタの起動
Pythonを実行するためにエディタが必要ですが、IDLEというアプリがPythonと一緒にインストールされているので、
そちらを使うのが早いです。
ただ、実際のコーディングの手間を考えると、下記のAtomなどの方が便利そうです。
こういうのは形から入るのが大事なので、インストールしてみました。
https://atom.io/
※Atomエディタを使用する場合、下記のパッケージをダウンロードしておくとよさそう
・japanese-menu
・script
・atom-runnner
コーディング
Atomエディタを起動して、実際にコーディングしてみます。
下記のプログラムファイルを作成して実行してみます。
ページが複数にわたるので、while文で繰り返し処理させることで全タイトルを抽出しました。
- #ライブラリのインポート
- import requests
- from bs4 import BeautifulSoup
- #Webページを取得(ページごと)
- base_url=”https://hamaotoko.com/page/”
- num = 1
- while num <= 50:
- url=base_url+ str(num)
- html = requests.get(url)
- #Webページを解析
- soup=BeautifulSoup(html.content, “html.parser”)
- titles =soup.select(“h2”)
- #最後のページで終了
- if len(titles) == 0:
- print(“最後のページ”)
- break
- #タイトル出力
- for element in soup.find_all(“h2”):
- print(element.text)
- #次のページ
- num += 1
実行結果
下記のように、ずらずらとタイトルが出力されました。
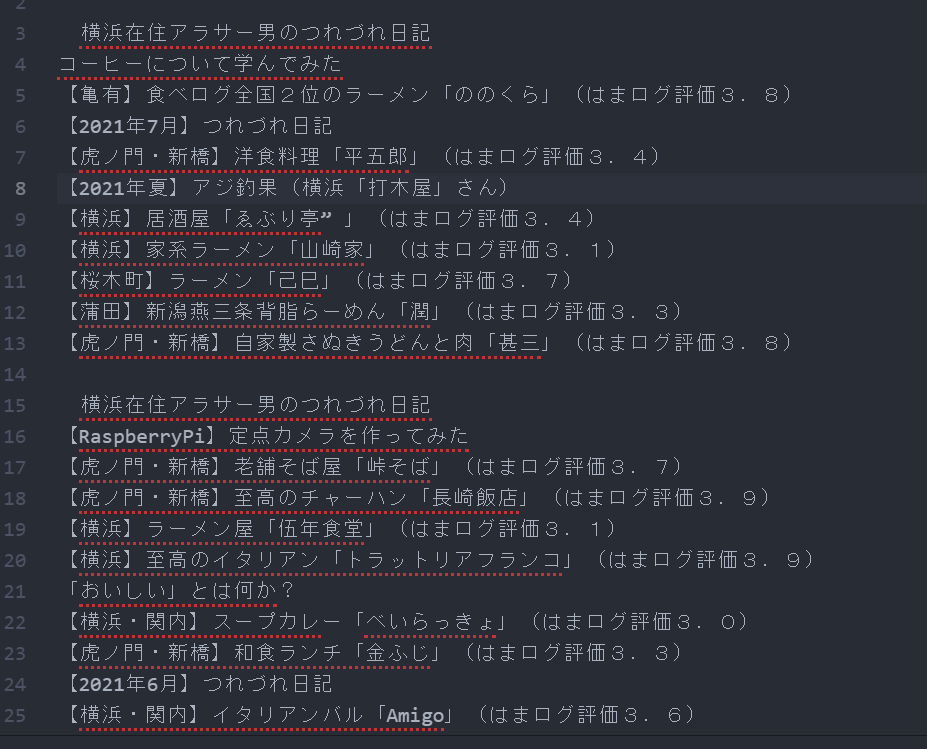
ヘッダーのタイトルが繰り返し出力されてしまった(スクリプトが悪い)が、疲れてしまったので、excelで加工。
結果、分かったこととしては下記のとおり。
- 記事数の総計は、353件!
- はまログ(食事)の記事は、そのうち245件!(全体の69%)
- 横浜のお店の記事は、124件!(全体の35%)
「浜男」と冠している割には、横浜の記事はあまり多くなかったことが分かった。
管理画面上では把握できず、スクレイピングによって初めて把握することができた。
本記事のように技術的なことも今後はアウトプットを増やしていきたいものです。